Local AI Engine (llama.cpp)
llama.cpp is the engine that runs AI models locally on your computer. It's what makes Jan work without needing internet or cloud services.
Accessing Engine Settings
Find llama.cpp settings at Settings () > Local Engine > llama.cpp:
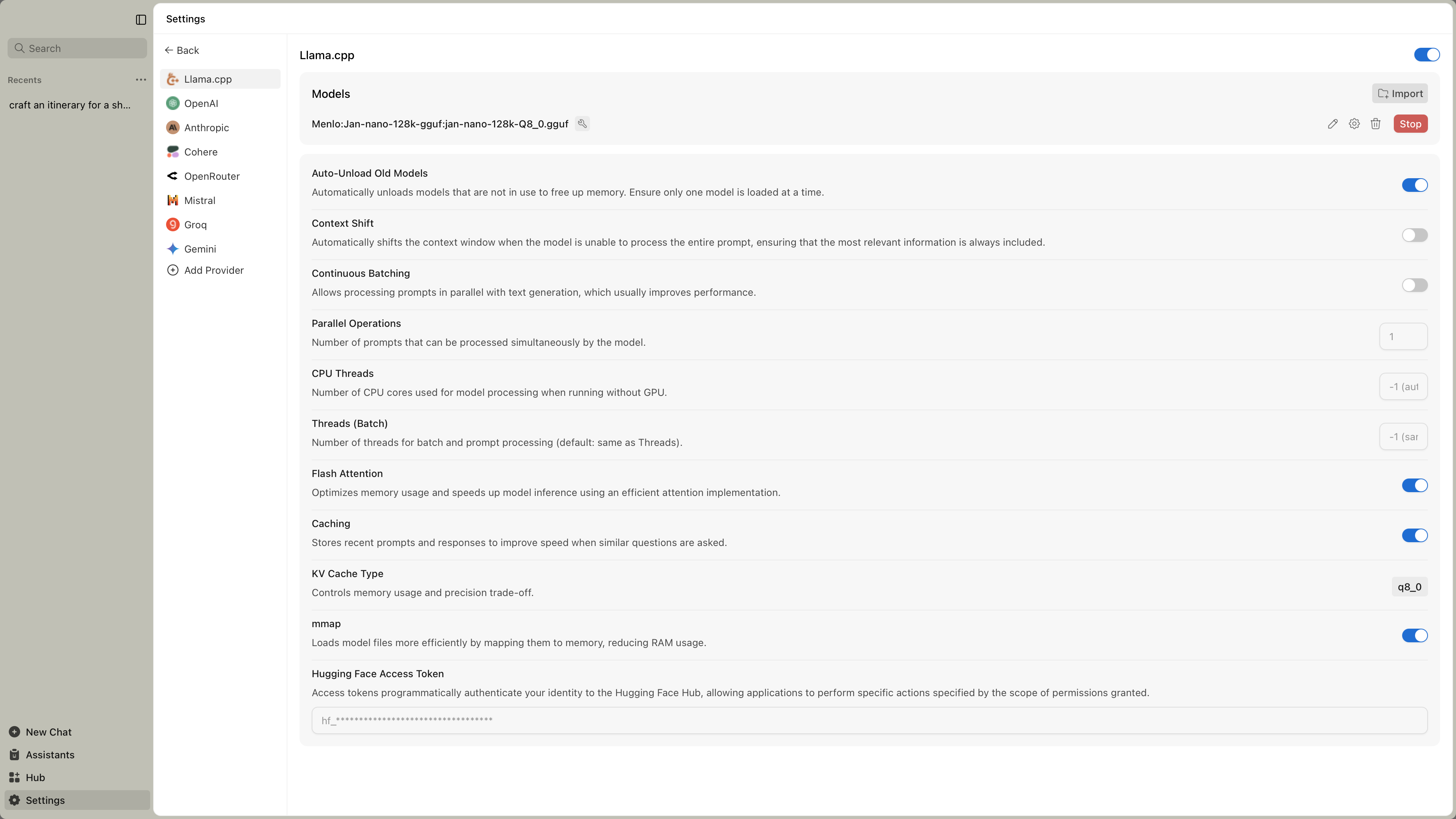
Most users don't need to change these settings. Jan picks good defaults for your hardware automatically.
When to Adjust Settings
You might need to modify these settings if:
- Models load slowly or don't work
- You've installed new hardware (like a graphics card)
- You want to optimize performance for your specific setup
Engine Management
| Feature | What It Does | When You Need It |
|---|---|---|
| Engine Version | Shows current llama.cpp version | Check compatibility with newer models |
| Check Updates | Downloads engine updates | When new models require updated engine |
| Backend Selection | Choose hardware-optimized version | After hardware changes or performance issues |
Hardware Backends
Different backends are optimized for different hardware. Pick the one that matches your computer:
NVIDIA Graphics Cards (Fastest)
For CUDA 12.0:
llama.cpp-avx2-cuda-12-0(most common)llama.cpp-avx512-cuda-12-0(newer Intel/AMD CPUs)
For CUDA 11.7:
llama.cpp-avx2-cuda-11-7(older drivers)
CPU Only
llama.cpp-avx2(modern CPUs)llama.cpp-avx(older CPUs)llama.cpp-noavx(very old CPUs)
Other Graphics Cards
llama.cpp-vulkan(AMD, Intel Arc)
Performance Settings
| Setting | What It Does | Recommended | Impact |
|---|---|---|---|
| Continuous Batching | Handle multiple requests simultaneously | Enabled | Faster when using tools or multiple chats |
| Parallel Operations | Number of concurrent requests | 4 | Higher = more multitasking, uses more memory |
| CPU Threads | Processor cores to use | Auto | More threads can speed up CPU processing |
Memory Settings
| Setting | What It Does | Recommended | When to Change |
|---|---|---|---|
| Flash Attention | Efficient memory usage | Enabled | Leave enabled unless problems occur |
| Caching | Remember recent conversations | Enabled | Speeds up follow-up questions |
| KV Cache Type | Memory vs quality trade-off | f16 | Change to q8_0 if low on memory |
| mmap | Efficient model loading | Enabled | Helps with large models |
| Context Shift | Handle very long conversations | Disabled | Enable for very long chats |
Memory Options Explained
- f16: Best quality, uses more memory
- q8_0: Balanced memory and quality
- q4_0: Least memory, slight quality reduction
Quick Troubleshooting
Models won't load:
- Try a different backend
- Check available RAM/VRAM
- Update engine version
Slow performance:
- Verify GPU acceleration is active
- Close memory-intensive applications
- Increase GPU Layers in model settings
Out of memory:
- Change KV Cache Type to q8_0
- Reduce Context Size in model settings
- Try a smaller model
Crashes or errors:
- Switch to a more stable backend (avx instead of avx2)
- Update graphics drivers
- Check system temperature
Quick Setup Guide
Most users:
- Use default settings
- Only change if problems occur
NVIDIA GPU users:
- Download CUDA backend
- Ensure GPU Layers is set high
- Enable Flash Attention
Performance optimization:
- Enable Continuous Batching
- Use appropriate backend for hardware
- Monitor memory usage
The default settings work well for most hardware. Only adjust these if you're experiencing specific issues or want to optimize for your particular setup.