The Invisible Moat around Open-Source LLM
In the crowded AI landscape, OpenAI's ChatGPT stands out, not just for its capabilities but for its unique access to the pre-trained dataset. This post explores the vital role of data in maintaining a competitive edge, focusing on OpenAI's strategic advantage through data ownership.
Data: The Secret Weapon
OpenAI, with ChatGPT, has carved a distinct advantage. By harnessing user interactions, it gains invaluable insights into diverse use cases, enabling precise model refinements. The cornerstone of this advantage lies in the "pre-trained dataset." This treasure trove of data empowers OpenAI to cater to specific needs, ensuring sustained improvement and differentiation.
The rise of the opensource
- How they/Mistral/Llama make money?-> around having pretrained data -> finetuningFirst para:Rise of Open Source LLMs like Mistral, Llama2, Llama3People think they don't have a moat = everything is open sourceSecond para:We actually think these guys have an "invisible moat"Pre-training data is not released, and makes a huge difference in fine-tuning efficacy
Why pretrained data is important?
Owning the pre-trained dataset is crucial as it represents the original distribution. Access to the pre-trained dataset acts as a master key to address the critical issue of "Catastrophic forgetting" (opens in a new tab) in Language Learning Models (LLMs). This phenomenon describes how LLMs lose hold of prior knowledge upon learning new information. Access to the foundational dataset allows for effective fine-tuning, balancing the introduction of new data with the retention of existing knowledge.

Figure 1. Demonstrates the catastrophic forgetting issue: without mixing datasets, AI overfits on new tasks, impairing normal communication.
Illustrating Catastrophic Forgetting
What is fine-tuningProcess of Finetuning (pretrain, instruct, finetune)Fine-tuning datasetsRisk of catastrophic forgetting"Why is Pre-trained data important?"What is pre-training datasetHow does fine-tuning with pre-training dataset differ from when you don't have itHow does it avoid catastrophic forgetting
Catastrophic forgetting can be visualized as a ball in a multidimensional landscape, where moving towards new knowledge risks losing grasp on the old. Pre-trained data acts as a map, guiding fine-tuning in a way that incorporates new information while safeguarding existing knowledge.
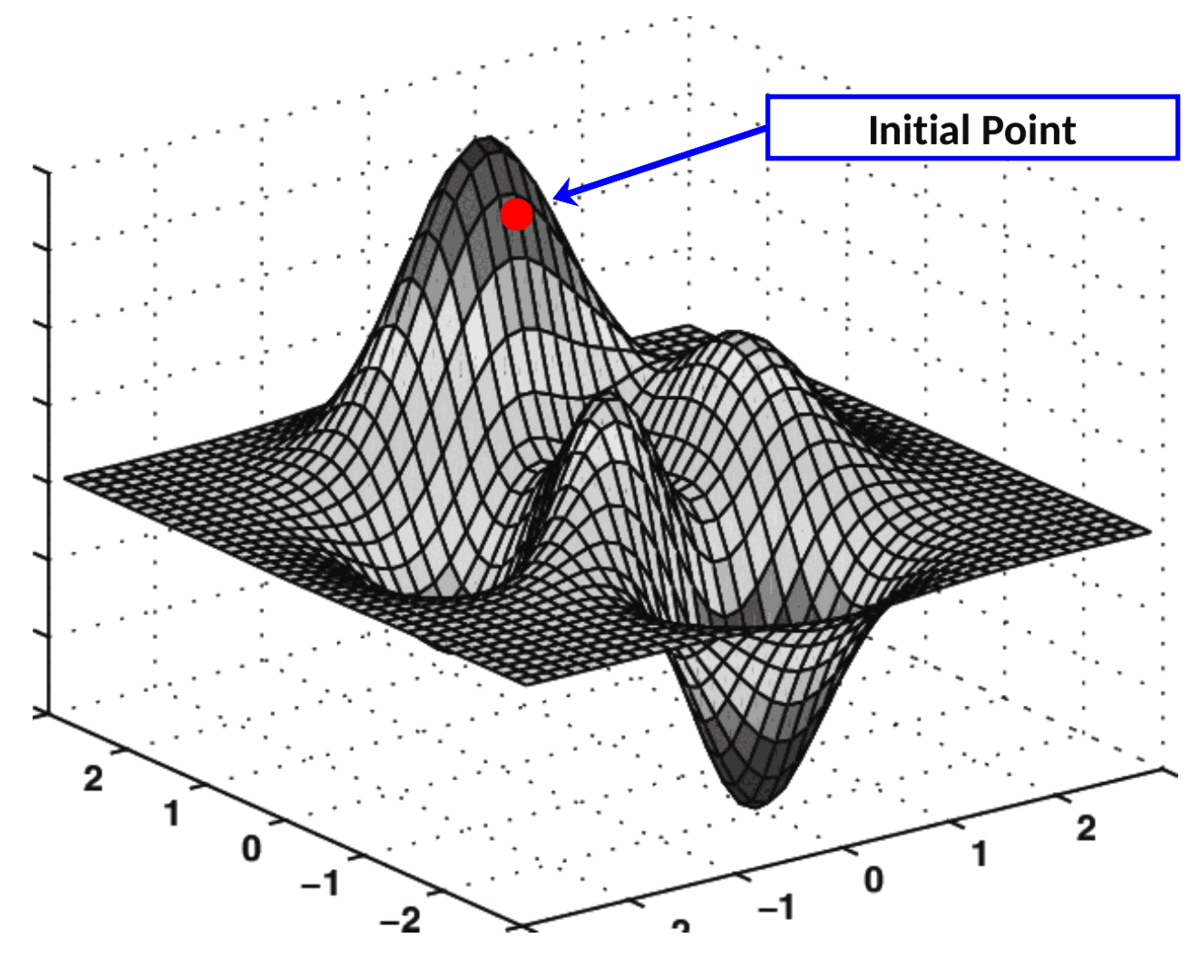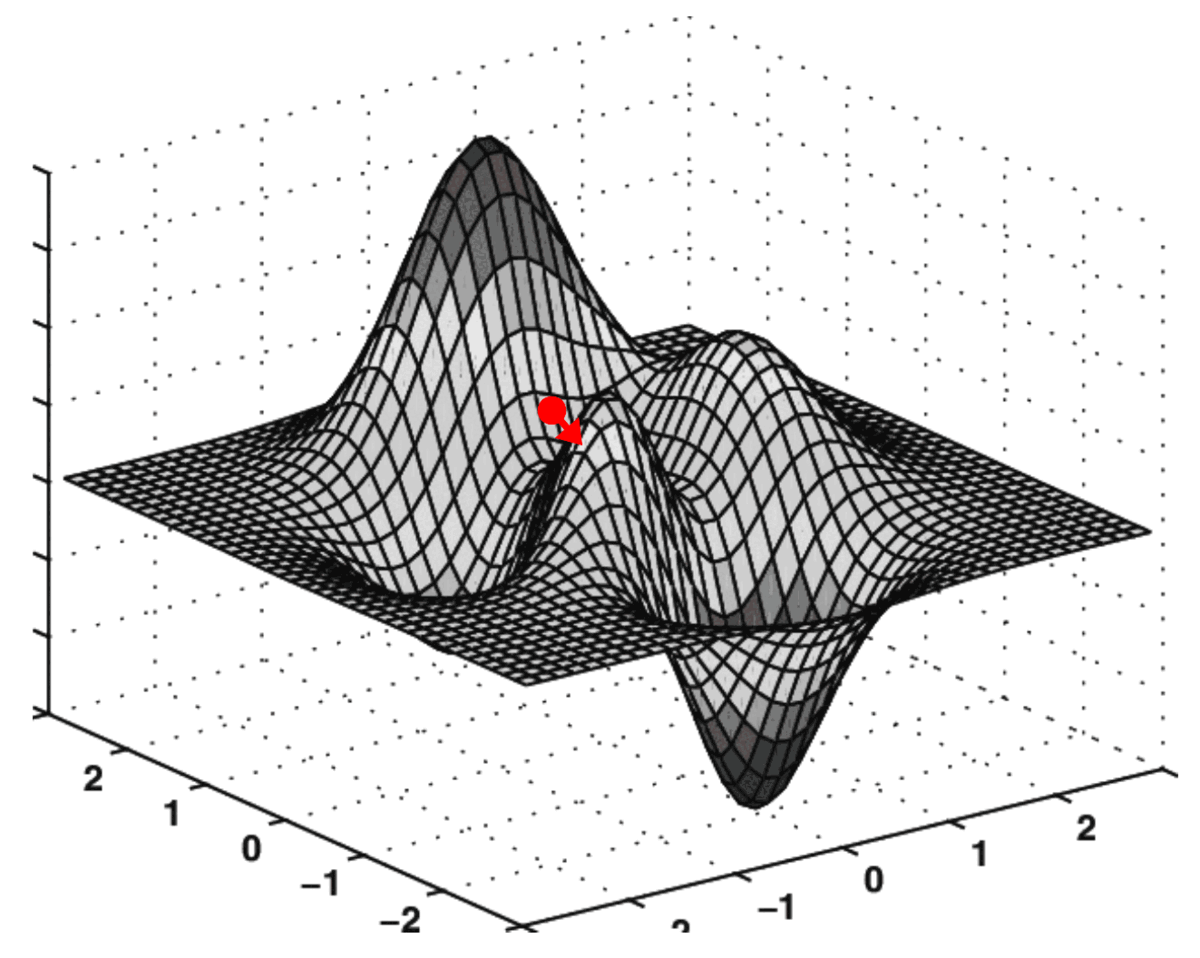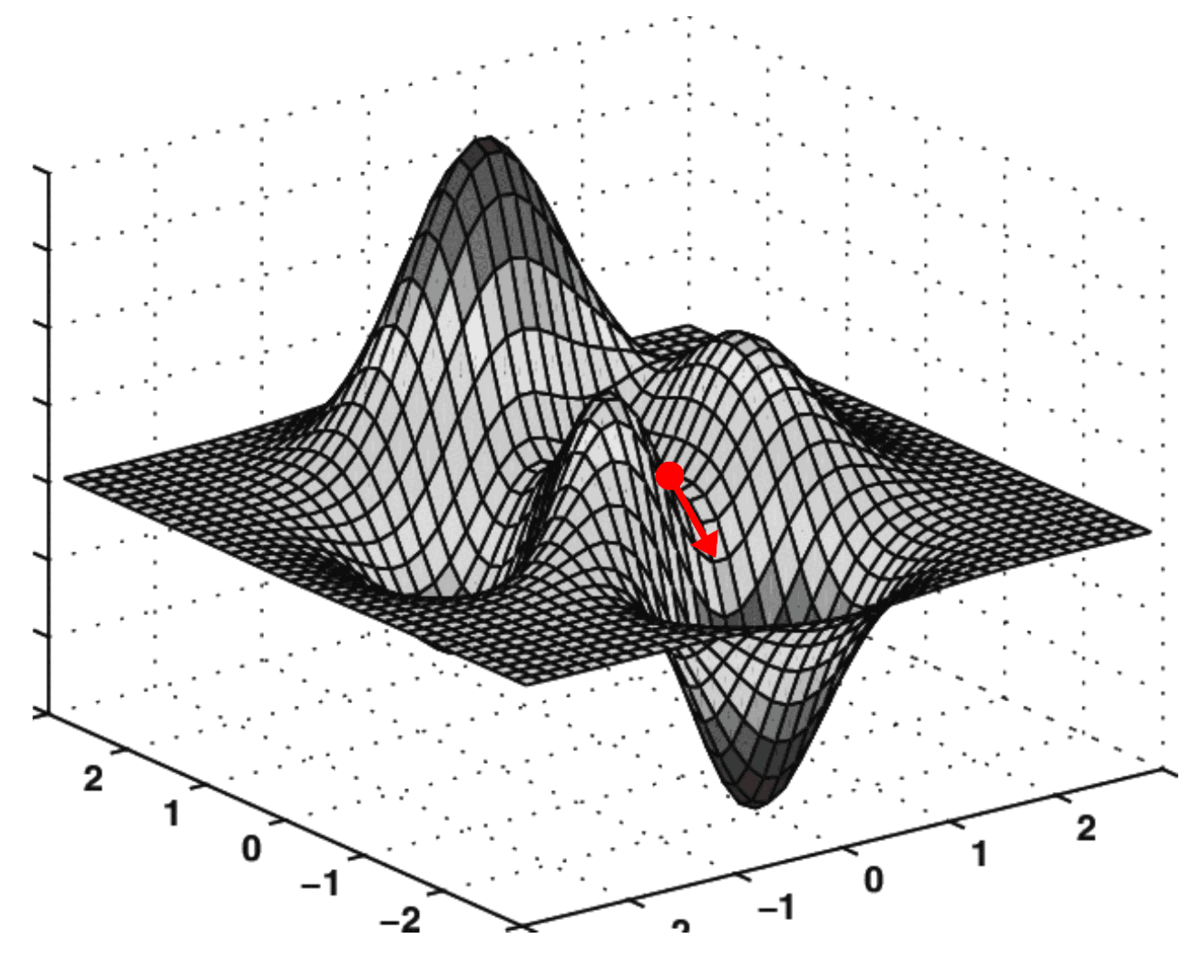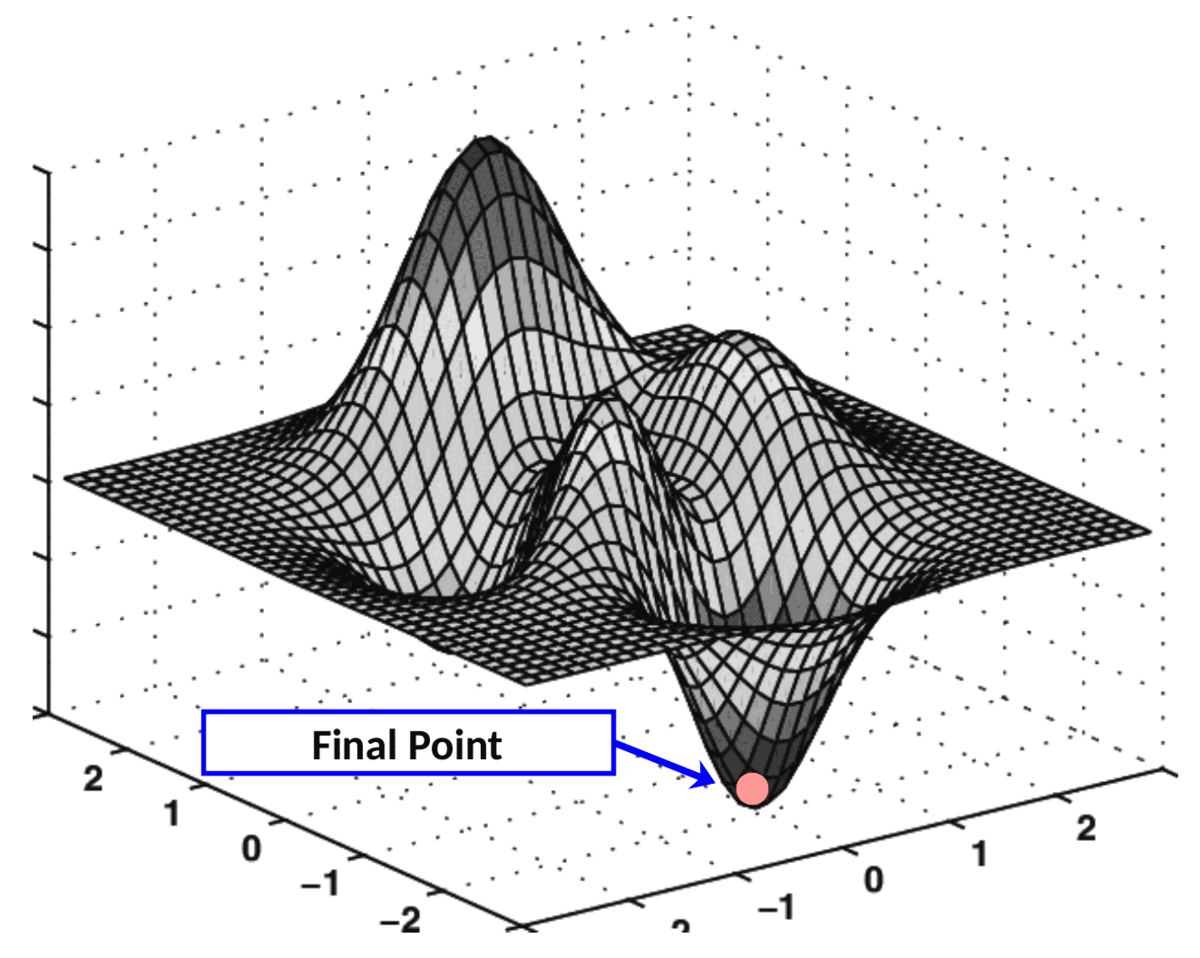
Figure 2. Gradient decent demonstration (opens in a new tab)
Smoothing Distribution Shifts
As described above, with the mixture of the pre-trained dataset ensures smoother distribution shifts when introducing new information, as it embodies a comprehensive spectrum of prior knowledge.
This continuity in knowledge transition helps in maintaining the robustness of the model against sudden changes, akin to providing a more gradual learning curve where the new information is incrementally integrated with the existing knowledge base.
This concept is supported by the EleutherAI's research (opens in a new tab) highlighting the importance of how tasks are sequenced in the learning process, suggesting that introducing dissimilar tasks early on can expand the network's capacity for new information.
Table 1. Final results for English-only 405M parameter models trained with different replay amounts show models with more replay perform better in balancing learning and forgetting (measured as AVG Loss). Notably, just 1% mix with a pre-trained dataset significantly lowers AVG loss, effectively shifting model knowledge from English (the Pile) to German.
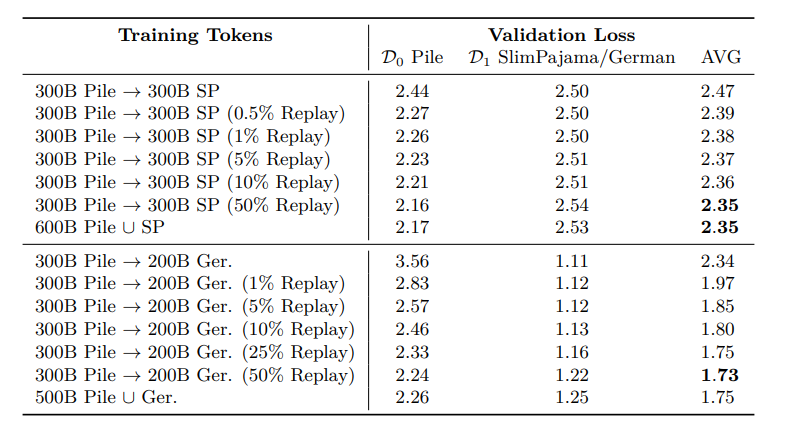
Note: Replay is the method involves combining the training dataset from the pre-trained model with new task datasets.
Acting as a Noise Mask
The pre-trained data can also serve as a form of "noise masking", similar to techniques used in training early computer vision models (opens in a new tab).
This approach introduces a level of "noise" (opens in a new tab) during training, which can prevent the model from overfitting to the new dataset. By retaining a mix of original and new data, the model is exposed to a broader range of scenarios, enhancing its generalization capabilities and robustness across tasks.
Solutions
Overwholming approach
Overcoming these challenges requires a balanced approach. One partial method involves inundating the model with extensive, curated data, allowing for comprehensive fine-tuning. While effective, this approach demands significant computational resources, a comprehensive filtering process for low-quality inputs, and an extraordinarily high cost associated with gathering millions of high-quality responses.
In the open-source community, 2 notable examples of fine-tuning with Mistral as a base model on large datasets collected from top-rated GPT-4 and human responses demonstrate a distribution shift that enhances model performance, including OpenChat (opens in a new tab) and Hermes-Pro (opens in a new tab).
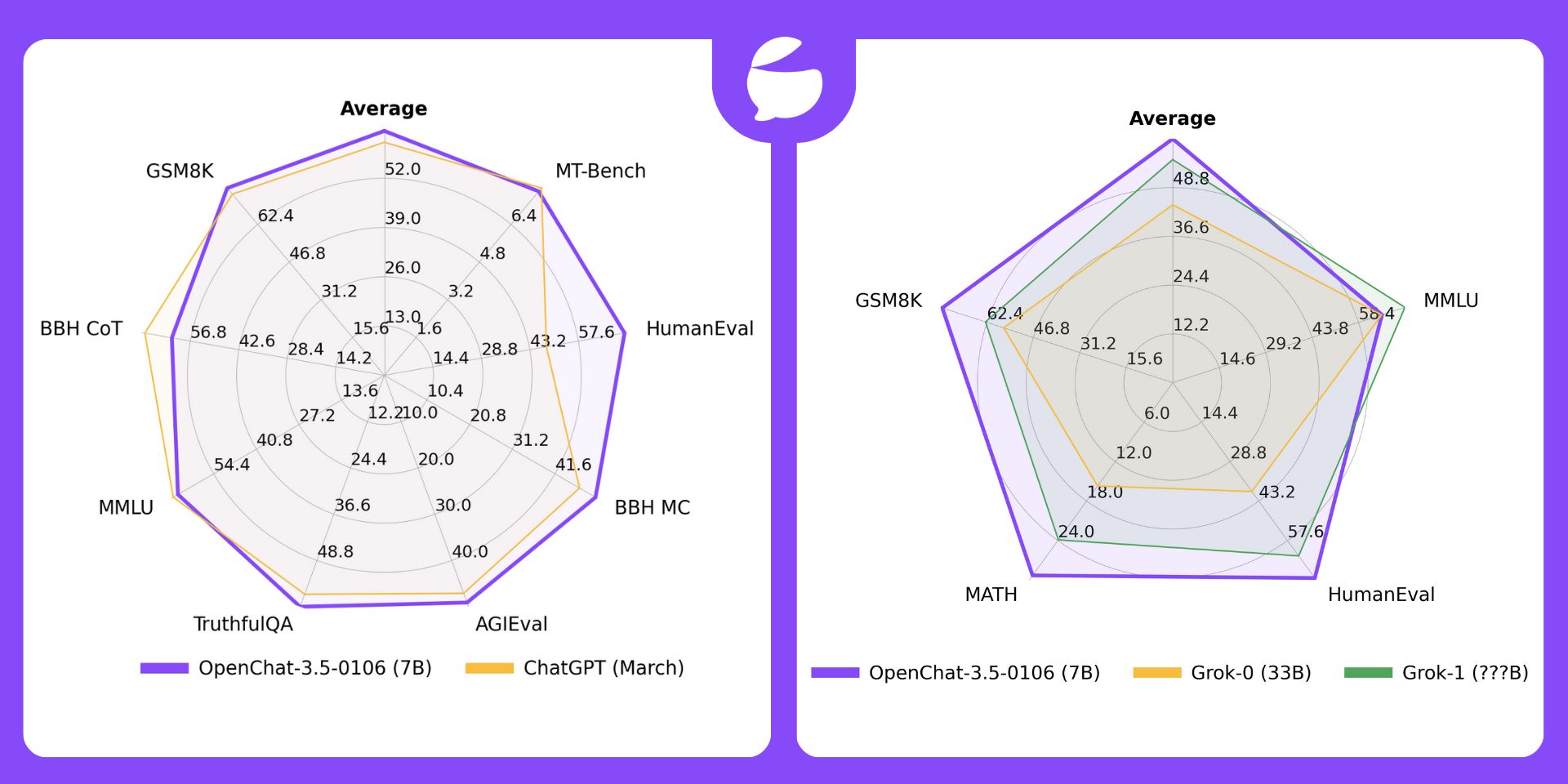
Figure 2. After fine-tuning with a large amount of data samples, the model's performance improved, outperforming ChatGPT and Grok-1 in some benchmarks.
Fully open source model
- Example: Dolma + olma from allenai
Conclusion
The ownership and strategic use of pre-trained data serve as an invisible moat. It not only enables the tackling of complex challenges like catastrophic forgetting but also provides a baseline for continuous, targeted improvements. Although there is a solution to decomotralize, the cost remains reasonably high.
Fully open pretrained + open weight
Reference
- Catastrophic forgetting (opens in a new tab)
- Simple and Scalable Strategies to Continually Pre-train Large Language Models (opens in a new tab)
- Gradient descent (opens in a new tab)
- Neftune (opens in a new tab)
- Self-training with Noisy Student improves ImageNet classification (opens in a new tab)


The Soul of a New Machine
To stay updated on all of Jan's research, subscribe to The Soul of a New Machine