Local AI Engine (llama.cpp)
What is llama.cpp?
llama.cpp is the engine that runs AI models locally on your computer. Think of it as the software that takes an AI model file and makes it actually work on your hardware - whether that's your CPU, graphics card, or Apple's M-series chips.
Originally created by Georgi Gerganov, llama.cpp is designed to run large language models efficiently on consumer hardware without requiring specialized AI accelerators or cloud connections.
Why This Matters
Privacy: Your conversations never leave your computer Cost: No monthly subscription fees or API costs Speed: No internet required once models are downloaded Control: Choose exactly which models to run and how they behave
Accessing Engine Settings
Find llama.cpp settings at Settings () > Local Engine > llama.cpp:
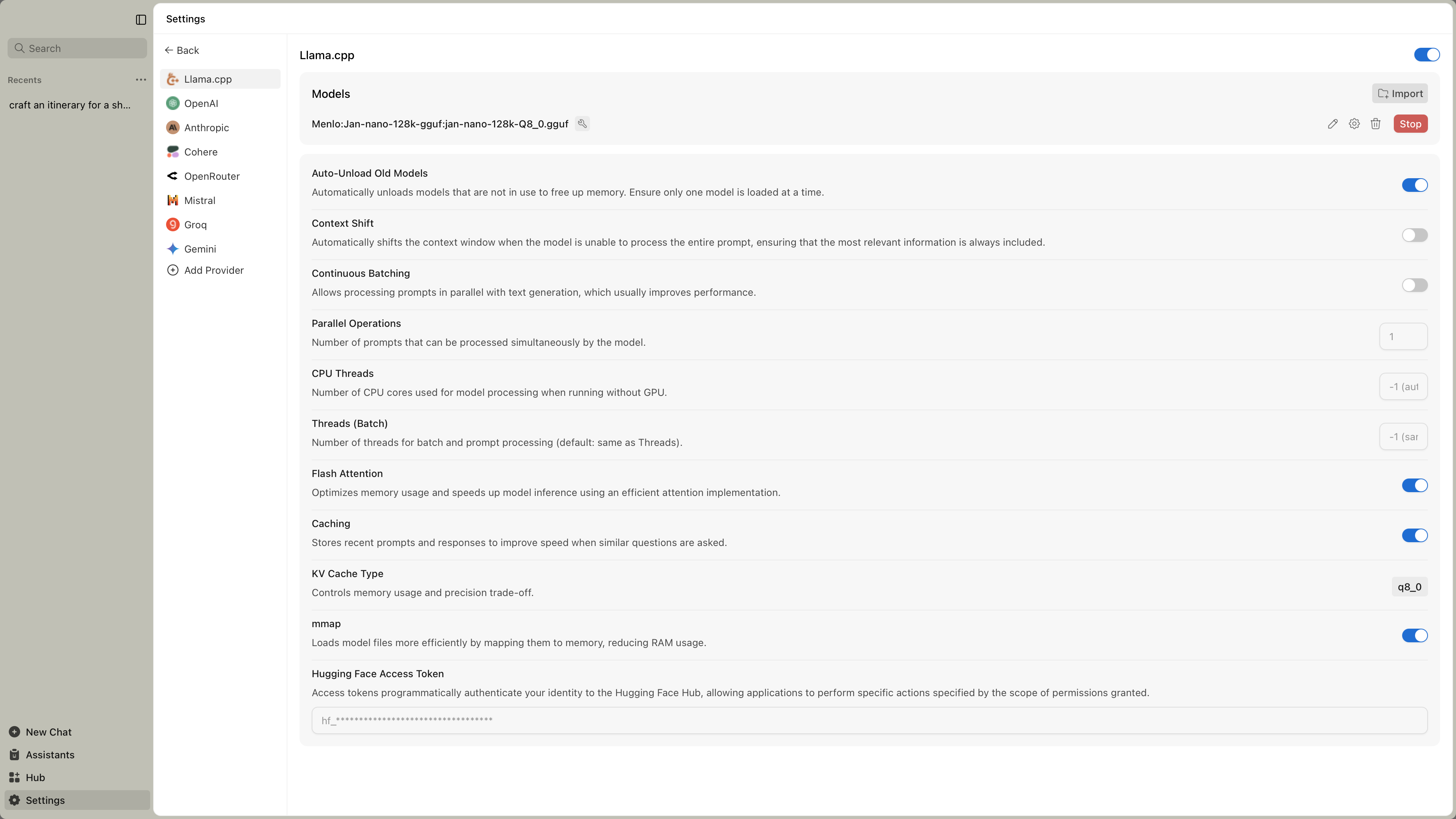
These are advanced settings. You typically only need to adjust them if models aren't working properly or you want to optimize performance for your specific hardware.
Engine Management
| Feature | What It Does | When You Need It |
|---|---|---|
| Engine Version | Shows which version of llama.cpp you're running | Check compatibility with newer models |
| Check Updates | Downloads newer engine versions | When new models require updated engine |
| Backend Selection | Choose the version optimized for your hardware | After installing new graphics cards or when performance is poor |
| Auto Update Engine | Automatically updates llama.cpp to latest version | Enable for automatic compatibility with new models |
| Auto-Unload Old Models | Unloads unused models to free memory | Enable when running multiple models or low on memory |
Hardware Backends
Jan offers different backend versions optimized for your specific hardware. Think of these as different "drivers" - each one is tuned for particular processors or graphics cards.
Using the wrong backend can make models run slowly or fail to load. Pick the one that matches your hardware.
NVIDIA Graphics Cards (Recommended for Speed)
Choose based on your CUDA version (check NVIDIA Control Panel):
For CUDA 12.0:
llama.cpp-avx2-cuda-12-0(most common)llama.cpp-avx512-cuda-12-0(newer Intel/AMD CPUs)
For CUDA 11.7:
llama.cpp-avx2-cuda-11-7(most common)llama.cpp-avx512-cuda-11-7(newer Intel/AMD CPUs)
CPU Only (No Graphics Card Acceleration)
llama.cpp-avx2(most modern CPUs)llama.cpp-avx512(newer Intel/AMD CPUs)llama.cpp-avx(older CPUs)llama.cpp-noavx(very old CPUs)
Other Graphics Cards
llama.cpp-vulkan(AMD, Intel Arc, some others)
Quick Test: Start with avx2-cuda-12-0 if you have an NVIDIA card, or avx2 for CPU-only. If it doesn't work, try the avx variant.
Performance Settings
These control how efficiently models run:
| Setting | What It Does | Recommended Value | Impact |
|---|---|---|---|
| Continuous Batching | Process multiple requests at once | Enabled | Faster when using multiple tools or having multiple conversations |
| Threads | Number of threads for generation | -1 (auto) | -1 uses all logical cores, adjust for specific needs |
| Threads (Batch) | Threads for batch and prompt processing | -1 (auto) | Usually same as Threads setting |
| Batch Size | Logical maximum batch size | 2048 | Higher allows more parallel processing |
| uBatch Size | Physical maximum batch size | 512 | Controls memory usage during batching |
| GPU Split Mode | How to distribute model across GPUs | Layer | Layer mode is most common for multi-GPU setups |
| Main GPU Index | Primary GPU for processing | 0 | Change if you want to use a different GPU |
Memory Settings
These control how models use your computer's memory:
| Setting | What It Does | Recommended Value | When to Change |
|---|---|---|---|
| Flash Attention | More efficient memory usage | Enabled | Leave enabled unless you have problems |
| Disable mmap | Don't memory-map model files | Disabled | Enable if experiencing crashes or pageouts |
| MLock | Keep model in RAM, prevent swapping | Disabled | Enable if you have enough RAM and want consistent performance |
| Context Shift | Handle very long conversations | Disabled | Enable for very long chats or multiple tool calls |
| Disable KV Offload | Keep KV cache on CPU | Disabled | Enable if GPU memory is limited |
| KV Cache K Type | Memory precision for keys | f16 | Change to q8_0 or q4_0 if running out of memory |
| KV Cache V Type | Memory precision for values | f16 | Change to q8_0 or q4_0 if running out of memory |
| KV Cache Defragmentation | Threshold for cache cleanup | 0.1 | Lower values defragment more often |
KV Cache Types Explained
- f16: Full 16-bit precision, uses more memory but highest quality
- q8_0: 8-bit quantized, balanced memory usage and quality
- q4_0: 4-bit quantized, uses least memory, slight quality loss
Advanced Settings
These settings are for fine-tuning model behavior and advanced use cases:
Text Generation Control
| Setting | What It Does | Default Value | When to Change |
|---|---|---|---|
| Max Tokens to Predict | Maximum tokens to generate | -1 (infinite) | Set a limit to prevent runaway generation |
| Custom Jinja Chat Template | Override model's chat format | Empty | Only if model needs special formatting |
RoPE (Rotary Position Embedding) Settings
| Setting | What It Does | Default Value | When to Change |
|---|---|---|---|
| RoPE Scaling Method | Context extension method | None | For models that support extended context |
| RoPE Scale Factor | Context scaling multiplier | 1 | Increase for longer contexts |
| RoPE Frequency Base | Base frequency for RoPE | 0 (auto) | Usually loaded from model |
| RoPE Frequency Scale Factor | Frequency scaling factor | 1 | Advanced tuning only |
Mirostat Sampling
| Setting | What It Does | Default Value | When to Change |
|---|---|---|---|
| Mirostat Mode | Alternative sampling method | Disabled | Try V1 or V2 for more consistent output |
| Mirostat Learning Rate | How fast it adapts | 0.1 | Lower for more stable output |
| Mirostat Target Entropy | Target perplexity | 5 | Higher for more variety |
Output Constraints
| Setting | What It Does | Default Value | When to Change |
|---|---|---|---|
| Grammar File | Constrain output format | Empty | For structured output (JSON, code, etc.) |
| JSON Schema File | Enforce JSON structure | Empty | When you need specific JSON formats |
Troubleshooting Common Issues
Models won't load:
- Try a different backend (switch from CUDA to CPU or vice versa)
- Check if you have enough RAM/VRAM
- Update to latest engine version
Very slow performance:
- Make sure you're using GPU acceleration (CUDA/Metal/Vulkan backend)
- Increase GPU Layers in model settings
- Close other memory-intensive programs
Out of memory errors:
- Reduce Context Size in model settings
- Switch KV Cache Type to q8_0 or q4_0
- Try a smaller model variant
Random crashes:
- Switch to a more stable backend (try avx instead of avx2)
- Disable overclocking if you have it enabled
- Update graphics drivers
Quick Setup Guide
For most users:
- Use the default backend that Jan installs
- Enable Auto Update Engine for automatic compatibility
- Leave all performance settings at defaults
- Only adjust if you experience problems
If you have an NVIDIA graphics card:
- Select the appropriate CUDA backend from the dropdown (e.g.,
avx2-cuda-12-0) - Make sure GPU Layers is set high in model settings
- Keep Flash Attention enabled
- Set Main GPU Index if you have multiple GPUs
If models are too slow:
- Check you're using GPU acceleration (CUDA/Metal/Vulkan backend)
- Enable Continuous Batching
- Increase Batch Size and uBatch Size
- Close other applications using memory
If running out of memory:
- Enable Auto-Unload Old Models
- Change KV Cache K/V Type to q8_0 or q4_0
- Reduce Context Size in model settings
- Enable MLock if you have sufficient RAM
- Try a smaller model
For advanced users:
- Experiment with Mirostat sampling for more consistent outputs
- Use Grammar/JSON Schema files for structured generation
- Adjust RoPE settings for models with extended context support
- Fine-tune thread counts based on your CPU
Most users can run Jan successfully without changing any of these settings. The defaults are chosen to work well on typical hardware.